输入网址后发生了什么?
1.首先是输入网址
2.浏览器查找域名对应IP
2.1 DNS查找过程
- 浏览器缓存——浏览器会记录DNS一段时间(2-30分钟不等,视浏览器而定)
- 系统缓存——浏览器里面没找到DNS缓存,此时浏览器做一个系统调用(Windows下是gethostbyname)。如发现匹配则采用。(与此对应有host恶意劫持更改攻击)
- 路由器缓存——路由器也会有DNS缓存(缓存你上过的网站,所以有时需要进行那个DNS刷新)
- ISP DNS缓存——接下来是在ISP(互联网服务提供商)的DNS服务器的缓存上查找。
- 递归查找——DNS缓存里没有的话,ISP DNS服务器会先后从根域名服务器(root)、.com顶级域名服务器、Google域名服务器获取IP(一般缓存内都会有,所以这一步一般不会发生)
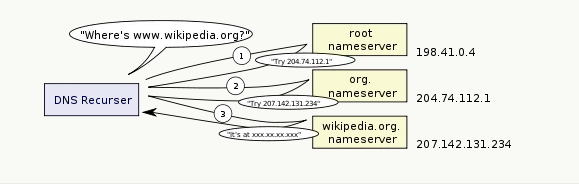
2.2 多IP域名DNS查询解决方案
- 循环DNS——单个域名、多个IP列表循环应对DNS查询
- 负载均衡器——一个特定的负载均衡服务器(例如:反向代理服务器)负责监听请求并转发给后面的多个服务器集群的某一个,实现多个服务器负载均衡
- 地理DNS——根据用户所处地理位置,返回不同的IP(应用:CDN)
- anycast——一个IP地址映射多个物理主机的路由技术
3.发送请求
得到域名对应IP后,就开始发送http(s)请求了。
请求头详解:
1 | GET http://google.com/ HTTP 1.1 |
请求告诉服务器:
- 我要获取(GET)http://google.com/ (GET的URL)这个页面
- Accept:我能接受这些类型的文件
- 我使用的是何种操作系统上的哪个类型哪个版本的浏览器
- 承认接受何种方式的压缩文件
- 连接类型:短连接?长连接?
- 主机域名
- 发送存储在本机的cookies信息给服务器
除了发送获取请求,还能发送提交响应请求(如:搜索时要把搜索的内容一并发给服务器进行处理(在请求url后面增加特定的用户参数),以获取特定的内容)
注意:url后面加斜杠与不加斜杠的区别(文件夹与单个文件的区别)
http://www.google.com
http://www.google.com/
当我们输入 http://www.google.com 时,浏览器会自动添加斜杠,保证URL的严谨
当我们输入:http://www.google.com/folderOrFile 时,因为浏览器不清楚folderOrFile到底是文件还是文件夹,所以不能自动添加 斜杠。这时,浏览器就不加斜杠直接访问地址,服务器会响应一个重定向,结果造成一次不必要的握手。
4.重定向
当我们输入不完整的网址 (http://google.com) 时,或者网站迁移做了重定向设置时,服务器会进行一次重定向响应。
下面是重定向之后返回的响应头:
1 | HTTP/1.1 301 Moved Permanently |
- 301永久重定向
- 新的Location:……
为什么要重定向,而不直接返回用户想看的内容?(既然服务器已经重定向知道了用户需要什么)
答:原因之一是与搜索引擎排名有关。比如,如果一个页面有两个地址,就像 http://www.igoro.com/ 和 http://igoro.com/ ,搜索引擎会认为它们是两个网站,结果造成每一个的搜索链接都减少从而降低排名。而搜索引擎知道301永久重定向是什么意思,这样就会把访问带www和不带www的地址归到同一个网站排名下。
5.新的请求
重定向之后会发布一个新的获取请求
6服务器处理请求
6.1 web服务器软件
- 服务器操作系统种类:Linux(一般是厂家根据开源定制)、windows server系列(微软)
- 主要的服务器软件:IIS、Apache、Tomcat、JBOSS、Nginx、lighttpd、Tetty
- 服务器软件的作用:接收、处理与相应请求(了解CGI的作用)
6.2 处理流程
- web服务器软件(如IIS或者Apache)接收到http请求
- 确定执行那个请求处理程序(一个能读懂请求并且能生成html来进行响应的程序)(例如:Asp.Net,PHP,RUBY)来处理它
- 请求处理器阅读请求头的参数cookies信息
- 更新服务器上的信息:例如更新数据库信息、服务端cookies
- 生成html,压缩(gzip或其它),响应请求发送给用户
7.服务器发回一个html响应
响应包括响应头(响应参数与信息)、响应包(主体文件)
响应包采用特定方法压缩,整个响应以blob类型传输,响应头只是响应包以何种方式压缩
这个响应头与重定向的响应头不太一样,这个响应头还包含着缓存选项,cookies设置和隐私信息等
8.浏览器开始显示html
浏览器在没有完整接收全部html文件时就已经开始显示页面了
9.浏览器获取其它文件
浏览器解析html遇到需要下载的文件时,便再次向服务器(CDN )发送获取文件的请求。
注意:
- 动态页面无法缓存,静态文件允许浏览器进行缓存。
- 静态文件本地有缓存时直接从本地读取
- 请求响应头内包含着静态文件保存的期限,浏览器知道下载的静态文件要静默保留多久
- 响应头还会有静态文件的ETag(相当于版本号),当浏览器发现请求的静态文件的响应头的ETag与现有的缓存文件不符时,变回再次向服务器获取静态文件。
10.浏览器发送异步(AJAX)请求
- WEB 2.0的一大特征就是页面显示完全后客户端仍旧与服务器端保持联系(keep-alive)
- 浏览器执行特定的JS代码会给服务器发送异步请求,获取罪行的动态消息,使得页面能保持较新的状态。
- http是一个请求-响应协议,只有在客户端发送请求,服务器端才能做出响应,而不能主动把消息或者文档发给客户。所以,要想保持页面处于最新的状态,需要定时进行轮询(定时发送AJAX请求以更新页面内容)
- AJAX请求十分容易更改,且用户十分容易自己制造和发送AJAX请求,所以没有验证码的没有IP限制条件的投票就是一个小游戏了。
- 优化小方案:如果服务器被轮询时没有新消息,它就不理这个客户端。而当请求尚未超时的情况下如果手法哦了该客户的性消息,服务器就找到未完成的请求,把新消息作为响应发送给客户端(这样就无需频繁地响应请求了)